아래 글에서 이어지는 내용이다.
foreverhappiness.tistory.com/35
[자연어 처리] 불용어(Stop Words) 처리하기 - Python3, Windows 10
아래 글에서 이어지는 내용이다. foreverhappiness.tistory.com/30 [자연어 처리] KoNLPy를 사용하여 형태소 분석 및 DTM 만들기 - Python3, Windows 10 (feat. Okt, Pandas, Scikit-Le 아래 글에서 이어지는 내용..
foreverhappiness.tistory.com
이번에는 Python3의 NetworkX 모듈을 사용하여 동시 출현 분석을 해보려고 한다.
어떤 주제의 신문 기사에 A라는 단어와 B라는 단어가 동시에 들어가 있을 때 두 단어는 연관성이 있다고 판단한다.
한 주제에 대해 모든 신문 기사를 조사했을 때 동시 출현하는 빈도수가 높을수록 그 두 단어의 연관성은 높아진다.
NetworkX는 단어들과 단어들 사이에 연관성이 깊은지, 또한 그 단어가 해당 주제와 얼마나 관련이 있는지 시각적으로 나타내 보여줄 수 있는 모듈이다.
먼저 cmd 혹은 명령 프롬프트 창을 열어 아래와 같이 입력해주자.
pip install networkx위 명령을 입력하면 networkx가 설치될 것이다.
단어 쌍의 빈도수를 알아보기 위해 우리는 DTM(Document Term Matrix)을 사용할 것이다.
사실 이외에도 동시 출현 빈도수를 파악하는 방법은 여러 가지 많다.
해당 방식은 최적이 아님을 미리 알린다.
혹시나 DTM파일이 없어서 필요하다면 아래 링크를 참고하길 바란다.
https://github.com/happiness96/Web-Crawling/tree/master/crawling
happiness96/Web-Crawling
Web Crawling, Text mining, Data mining (Using Python3) - happiness96/Web-Crawling
github.com
이제 아래 코드를 참고하여 단어 쌍 동시 출현 빈도수를 파악해보자.
# -*- encoding: utf-8 -*-
import pandas as pd
from tqdm import tqdm
if __name__ == '__main__':
# 단어쌍의 빈도를 체크하기위해 DTM을 불러온다.
dataset = pd.read_csv('D:\crawling\DTM.csv')
# 단어들의 목록을 가져온다.
# 이때 0번째 인덱스에는 빈 칸이 들어오므로 인덱싱을 통해 없애준다.
column_list = dataset.columns[1:]
word_length = len(column_list)
# 각 단어쌍의 빈도수를 저장할 dictionary 생성
count_dict = {}
for doc_number in tqdm(range(len(dataset)), desc='단어쌍 만들기 진행중'):
tmp = dataset.loc[doc_number] # 현재 문서의 단어 출현 빈도 데이터를 가져온다.
for i, word1 in enumerate(column_list):
if tmp[word1]: # 현재 문서에 첫번째 단어가 존재할 경우
for j in range(i + 1, word_length):
if tmp[column_list[j]]: # 현재 문서에 두번째 단어가 존재할 경우
count_dict[column_list[i], column_list[j]] = count_dict.get((column_list[i], column_list[j]), 0) + max(tmp[word1], tmp[column_list[j]])
# count_list에 word1, word2, frequency 형태로 저장할 것이다.
count_list = []
for words in count_dict:
count_list.append([words[0], words[1], count_dict[words]])
# 단어쌍 동시 출현 빈도를 DataFrame 형식으로 만든다.
df = pd.DataFrame(count_list, columns=["word1", "word2", "freq"])
df = df.sort_values(by=['freq'], ascending=False)
df = df.reset_index(drop=True)
# 이 작업이 오래 걸리기 때문에 csv파일로 저장 후 사용하는 것을 추천한다.
df.to_csv('D:\crawling\\networkx.csv', encoding='utf-8-sig')
DTM의 행은 문서의 번호, 열은 각 단어를 의미하며 해당 문서에 각 단어가 출현한 빈도수를 나타낸 것이 DTM이다.
각 문서별로 출현한 단어 쌍을 계산해 count_dict에 누적시키면 모든 문서에 대해 출현한 단어 쌍의 빈도수를 계산할 수 있다.
우리가 DTM을 만들 때 "화재 및 폭발 가능성"에 대한 단어들만 분류했었다.
이 작업을 거치고 나면 이 주제에 대해 어떤 단어들이 서로 연관성이 있고 어떤 단어들이 이 주제와 관련이 깊은지를 파악할 수 있다.
빈도수를 계산할 때 이 방법은 시간이 많이 걸린다. 즉 비효율적이라 다른 효율적인 방법이 많다.
현재 상황에서는 그 쉬운 방법을 구현하기 까다롭기 때문에 이 방법을 채택했다.
추후에 기회가 된다면 다른 효율적인 방법들도 올려보도록 하겠다.
시간이 오래 걸리다 보니 이를 DataFrame으로 만들어 csv파일로 저장해놓고 사용하기로 결정했다.
이제 이것으로 Networkx를 그릴 수 있다.
시각화하기 전에 몇 가지 알고 가야 할 개념들이 있다.
네트워크를 구성하는 중심성을 결정하는 몇 가지 척도들이 있는데 Networkx에서 이것들을 모두 제공하고 있기 때문에 짚고 넘어가야 할 부분이다.
네트워크 그래프적으로 생각한다면 연관어, 관련어 한 쌍이 함께 등장하는 횟수는 그래프에서 간선(Edge)에 해당하며 단어 하나는 node에 해당하고 단어가 등장하는 횟수는 node의 size로 볼 수 있다.
- 연결 중심성 (Degree Centrality)
연결된 노드가 많을수록 중심성의 크기가 커진다는 관점을 가진다.
여기서는 관련어, 연관어의 개수를 통해 해당 단어가 얼마나 중요한지를 노드의 크기를 통해 나타 낼 수 있다.
- 매개 중심성 (Betweenness Centrality)
노드와 노드 사이의 최단 경로를 계산할 때 해당 노드를 얼마나 거쳐가는가를 척도로 한다.
여기서는 크게 쓸 일이 없을 것이다.
- 근접 중심성 (Closeness Centrality)
다른 노드들까지의 최단 경로가 가까울수록 해당 노드가 중요하다는 척도를 가진다.
여기서는 연관어들 사이에 얼마나 연관성이 깊은지를 판단할 수 있을 것이다.
- 고유 벡터 중심성 (Eigenvector Centrality)
연결 중심성과 약간 비슷하다.
차이가 있다면 연결된 다른 노드의 중심성도 고려한다는 것이다.
중심성의 크기가 큰 노드들과 많이 연결될수록 중요하다고 판단한다.
- 페이지 랭크 (Page Rank)
다른 노드의 중심성과 연결되어있는 다른 노드의 개수에 따라 해당 노드의 중심성 크기를 상대적으로 결정하는 알고리즘이다.
여기서 상대적으로 결정한다는 것은 한 노드의 중심성이 A라고 한다면 연결되어있는 다른 노드의 중심성의 크기를 결정할 때 일정한 임의의 수로 나눠 A / x의 중심성을 가지게 된다. (물론 연결되어있는 다른 노드들도 많기 때문에 이 상대적인 값은 계속해서 조정된다.)
지금까지 등장한 중심성 알고리즘 중 가장 최적화된 알고리즘이다.
자 이제 아래 코드를 참고하여 단어 네트워크를 그려보자.
# -*- encoding: utf-8 -*-
import pandas as pd
import networkx as nx
import operator
import numpy as np
if __name__ == '__main__':
# 단어쌍 동시출현 빈도수를 담았던 networkx.csv파일을 불러온다.
dataset = pd.read_csv('D:\crawling\\networkx.csv')
# 중심성 척도 계산을 위한 Graph를 만든다
G_centrality = nx.Graph()
# 빈도수가 20000 이상인 단어쌍에 대해서만 edge(간선)을 표현한다.
for ind in range((len(np.where(dataset['freq'] >= 20000)[0]))):
G_centrality.add_edge(dataset['word1'][ind], dataset['word2'][ind], weight=int(dataset['freq'][ind]))
dgr = nx.degree_centrality(G_centrality) # 연결 중심성
btw = nx.betweenness_centrality(G_centrality) # 매개 중심성
cls = nx.closeness_centrality(G_centrality) # 근접 중심성
egv = nx.eigenvector_centrality(G_centrality) # 고유벡터 중심성
pgr = nx.pagerank(G_centrality) # 페이지 랭크
# 중심성이 큰 순서대로 정렬한다.
sorted_dgr = sorted(dgr.items(), key=operator.itemgetter(1), reverse=True)
sorted_btw = sorted(btw.items(), key=operator.itemgetter(1), reverse=True)
sorted_cls = sorted(cls.items(), key=operator.itemgetter(1), reverse=True)
sorted_egv = sorted(egv.items(), key=operator.itemgetter(1), reverse=True)
sorted_pgr = sorted(pgr.items(), key=operator.itemgetter(1), reverse=True)
# 단어 네트워크를 그려줄 Graph 선언
G = nx.Graph()
# 페이지 랭크에 따라 두 노드 사이의 연관성을 결정한다. (단어쌍의 연관성)
# 연결 중심성으로 계산한 척도에 따라 노드의 크기가 결정된다. (단어의 등장 빈도수)
for i in range(len(sorted_pgr)):
G.add_node(sorted_pgr[i][0], nodesize=sorted_dgr[i][1])
for ind in range((len(np.where(dataset['freq'] > 20000)[0]))):
G.add_weighted_edges_from([(dataset['word1'][ind], dataset['word2'][ind], int(dataset['freq'][ind]))])
# 노드 크기 조정
sizes = [G.nodes[node]['nodesize'] * 500 for node in G]
options = {
'edge_color': '#FFDEA2',
'width': 1,
'with_labels': True,
'font_weight': 'regular',
}
# 폰트 설정을 위한 font_manager import
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
# 폰트 설정
fm._rebuild() # 1회에 한해 실행해준다. (폰트 새로고침, 여러번 해줘도 관계는 없다.)
font_fname = './utils/NanumGothic.ttf' # 여기서 폰트는 C:/Windows/Fonts를 참고해도 좋다.
fontprop = fm.FontProperties(fname=font_fname, size=18).get_name()
nx.draw(G, node_size=sizes, pos=nx.spring_layout(G, k=3.5, iterations=100), **options, font_family=fontprop) # font_family로 폰트 등록
ax = plt.gca()
ax.collections[0].set_edgecolor("#555555")
plt.show()
코드에서는 페이지 랭크에 따라 중심성의 크기를 결정했다.
이외에도 근접 중심성을 사용해도 나쁘지 않다.
코드 실행 결과는 아래와 같다.
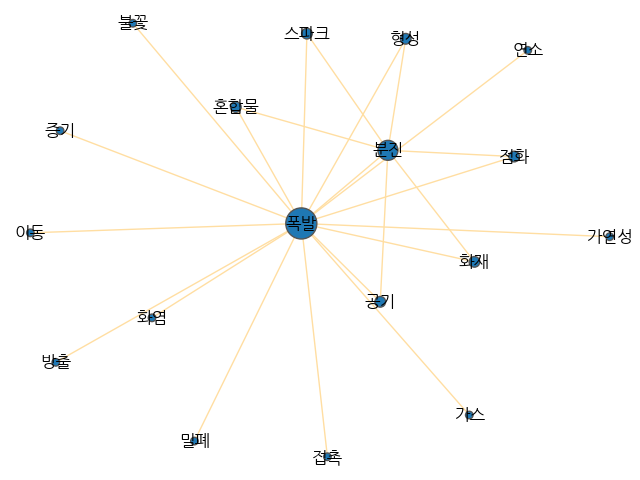
노드의 크기는 해당 단어의 연결 중심성 크기를 나타낸 것이며 이는 해당 단어가 얼마나 많이 출현했는지, 즉 얼마나 중요한지를 말해준다.
그리고 Edge(간선)의 길이는 두 노드 사이의 페이지 랭크 척도를 나타낸 것이며 두 단어 사이의 연관성이 얼마나 가까운지를 말해준다.
현재 결과에서는 폭발이라는 단어가 "화재 및 폭발 가능성"에서 가장 많이 출현한 단어가 될 것이며, 이와 관련이 깊은 단어로는 공기, 분진, 화재 등이 있다고 볼 수 있다.
지금은 단어 쌍의 빈도수가 20000 이상인 것들만 나타내었지만 이를 조정하면 그래프는 달라질 수 있다.
이번에는 19700으로 조정하여 실행해보았다.

단어와 단어 사이의 연관성을 시각적으로 한눈에 알아볼 수 있다.
지금까지 NetworkX 모듈을 사용하여 단어 동시 출현 빈도 분석, 연관어 분석을 해보았다.
NetworkX는 꼭 단어와 단어 사이의 관계가 아니더라도 Node(노드)와 Edge(간선)으로 표현될 수 있는 데이터라면 뭐든 시각적으로 분석이 가능할 것이다.
