0. 들어가기 전에
보통 데이터베이스라고 하면 관계형 데이터베이스인 MySQL, Oracle, Maria DB 등을 많이 떠올릴 것이다. IT 학과의 정규 교육과정에서도 보통 이를 주로 다룬다.
IT 정규 코스를 밟았다 하더라도 이 시계열 데이터베이스(TSDB)에 대해서는 아마 생소할 것이다.
사실 TSDB가 대두된 지는 꽤나 되었는데 이제야 제대로 접할 기회가 생겨서 이렇게 정리를 해본다.
먼저 시계열이라는 말부터가 조금 어렵게 다가올 수 있을 것 같다.
시계열이란, 시간의 흐름에 따라서 기록된 자료(데이터)들의 수열을 말한다.
즉 데이터에 시간의 개념을 추가하는 것이라고 볼 수 있다.
1. TSDB란?
시계열 데이터베이스(TSDB, Time Series Database)란 시계열 데이터 즉, 시간(time)과 값(value)이 한 쌍을 이루는 데이터를 시간에 따라 순차적으로 저장하고 서비스하는 시스템을 말한다.
즉 해당 값이 언제 기록됐는지를 알 수 있다는 것이다.
TSDB의 종류에는 InfluxDB, Kdb+, Graphite, Prometheus, OpenTSDB, 한국의 MachBase 등이 있는데 이 중 InfluxDB를 가장 많이 사용하며 여기서도 InfluxDB를 가지고 다뤄볼 것이다.
성능면에서는 한국의 MachBase도 뛰어나고 대표님께서도 큰 자부심을 느끼고 있는 것 같아 보였다.
하지만 처음 사용하기에는 InfluxDB가 익히기 수월할 것이다.

2. 왜 사용할까?
사실 이 부분이 가장 중요하다.
TSDB의 데이터가 시간과 값을 한 쌍을 가진다는 것은 알겠는데 대체 이걸 왜 사용하며 RDB(관계형 데이터베이스)와 다른 점은 무엇인지, 주로 어떤 분야에 사용하는지를 여기서 다뤄보고자 한다.
먼저 아래 그래프를 보자.
아래 그래프는 최근 2년동안의 DBMS에 대한 추세를 보여주고 있는 그래프이다.
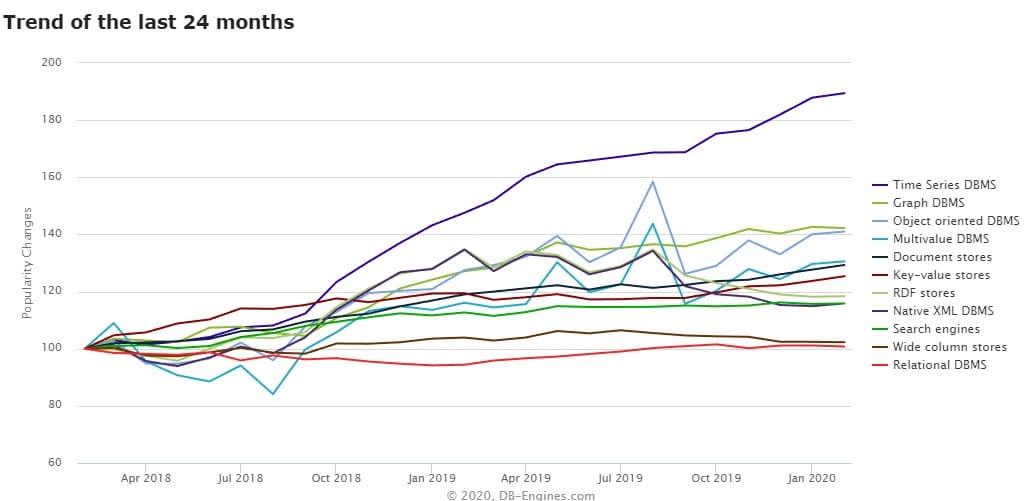
한눈에 봐도 TSDB에 대한 관심도가 높아지고 있는 추세인 것을 확인할 수 있다.
약 2018년도 10월경부터 TSDB에 대한 관심도가 높아지기 시작했는데 시계열 데이터에 대한 TSDB의 처리 능력도 함께 상승하였다.
이런 동향에 가장 많은 영향을 미친 것이 스마트 팩토리, 빅데이터와 같은 것들이다.
4차 산업혁명이 시작되고 난 이후로 데이터에 대한 가치가 높아지면서 데이터를 가공하고 다루고 처리하는 기술도 중요해지고 있다.
실제로 시계열 데이터에는 어떤 것들이 존재할까?
스마트 팩토리의 수많은 센서들로부터 나오는 센서 데이터, 실시간으로 변화하는 주가 데이터, 스마트 홈 시스템에서의 현재 온도 등이 있을 것이다.
이 데이터들의 특징이자 키워드로 뽑을 수 있는 단어가 바로 "실시간 데이터"라는 것이다.
TSDB, 시계열 데이터베이스는 이 실시간 데이터를 처리하는데 용이하다.
하드웨어, 센서의 기술이 발달하면서 센서 데이터를 읽어 들이는 속도까지 굉장히 빨라졌다.
실제로 어떤 스마트팩토리에서는 초당 700만 개, 하루에 252억 개의 데이터가 발생하고 자율주행 자동차 한 대가 하루에 수집하는 데이터의 양은 4000GB 이상 된다고 한다.
이런 수많은 데이터들을 처리하기에 기존의 관계형 데이터베이스로는 무리가 있다.
관계형 데이터베이스로 시계열 데이터를 저장하려면 시간과 값을 각각 따로 저장하여 이를 연관시켜야한다.
게다가 하나의 시간에 여러 종류의 데이터가 입력될 때, 데이터를 삭제할 때 굉장히 비효율적이고 느리게 처리된다.
데이터가 적은 경우에는 RDB로도 충분하지만 수많은 데이터를 처리해야 할 경우가 생기면서 TSDB의 관심도가 높아지게 된 것이다.
3. TSDB의 특징
TSDB의 특징에는 어떤 것들이 있는지 알아보자.
- 실시간 변화 추적에 용이하다.
실시간 데이터 처리를 통해 우리가 얻을 수 있는 것은 무엇일까?
과거와 현재의 데이터들을 토대로 미래의 데이터를 예측하고 이에 따른 판단을 할 수 있다.
실제로 인공지능, 데이터 분석 분야와 결합하여 굉장히 많이 사용되고 있다.
- 오래된 데이터를 삭제하기 편리하다.
RDB를 사용하면 오래된 데이터를 처리하기 번거로운 반면 TSDB는 1년, 5년 등 일정 시간이 지난 데이터 삭제가 편리하다.
- 데이터 입출력이 빠르다.
TSDB는 데이터를 빠르게 처리하기 위해 구조적으로 RDB와 다른 구조를 지닌다.
DB마다 약간씩 다르며 이 구조에 따라 DB의 성능이 결정되기도 한다.
RDB는 보통 B+Tree 구조를 가지며 TSDB는 주로 시간을 축으로 하는 파티션 형태의 구조를 가진다.
이외에 트랜잭션을 지원하지 않는 등 여러 가지 방법으로 속도를 향상한다.
4. 실제로 어디에 사용할까?
TSDB에는 데이터가 측정의 의미를 내포하고 있다.
실제로 우리 주위에 상상을 초월할 정도로 많은 데이터가 수집되고 있으며 엄청나게 많은 센서들이 동작하고 있다.
의식주는 물론이며 자동차, 의료기기, 건설, 인체, 금융 등 수많은 분야에서 실시간 데이터가 측정되고 있다.
이러한 데이터들은 변화에 따라 특정한 조치를 취해줘야 한다.
예를 들면 스마트홈의 현재 온도 데이터를 통해 보일러 또는 에어컨을 조절할 수 있고, 스마트워치의 심박 센서를 통해 사용자에게 달리는 속도를 늦출 수 있도록 알릴 수도 있으며 충돌 방지 센서가 탑재된 자동차에서는 실시간으로 주변의 물체를 탐지하여 자동으로 브레이크를 작동시킬 수도 있다.
5. 마무리
TSDB의 힘은 앞으로도 많이 커질 것이고 사용되는 분야는 더욱 광범위해질 것이다..
현재까지도 TSDB에 저장된 실시간 데이터를 시각화해주는 오픈소스가 많이 나와있으며 계속해서 업데이트 중이다.
지금 이 순간에도 데이터는 계속해서 수집되고 있고 모니터링되고 있으며 분석되고 있으며 의사가 결정되고 있다.
