0. 들어가기 전에
아직 InfluxDB가 설치되어있지 않거나 시계열 데이터베이스에 대해 잘 모른다면 아래 게시글을 참고하자.
foreverhappiness.tistory.com/59
InfluxDB 소개 및 설치 (For Windows & Ubuntu)
0. 들어가기 전에 시계열 데이터베이스(TSDB, Time-Series Database) 중에서 가장 많이 사용되는 InfluxDB를 다뤄볼 것이다. TSDB에 대해 아직 잘 모른다면 아래 링크를 참고하길 바란다. foreverhappiness.tistor..
foreverhappiness.tistory.com
foreverhappiness.tistory.com/58
시계열 데이터베이스(TSDB, Time Series Database)란 무엇인가?
0. 들어가기 전에 보통 데이터베이스라고 하면 관계형 데이터베이스인 MySQL, Oracle, Maria DB 등을 많이 떠올릴 것이다. IT 학과의 정규 교육과정에서도 보통 이를 주로 다룬다. IT 정규 코스를 밟았다
foreverhappiness.tistory.com
이번 포스팅에서는 influxDB를 구축하고 데이터를 생성하는 등 사용방법에 대해 알아볼 것이다.
1. 데이터베이스 생성
데이터베이스를 다루기 위해 지금부터 쿼리문을 사용할 것이다.
데이터베이스를 생성할 때는 다음과 같이 입력하면 된다.
DBNAME에는 생성하고자 하는 데이터베이스의 이름을 넣어주면 된다.
CREATE DATABASE [DBNAME]

2. 데이터베이스 목록 확인
생성한 데이터베이스들을 확인하려면 아래와 같이 입력하면 된다.
SHOW DATABASES
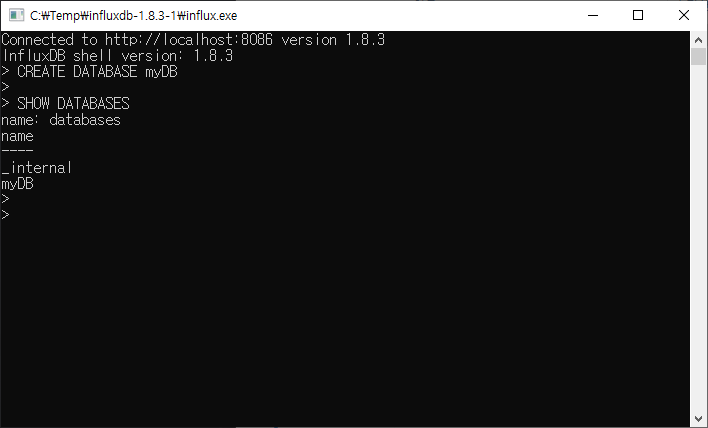
처음 생성할 때는 _internal과 생성한 DB만 있을 것이다.
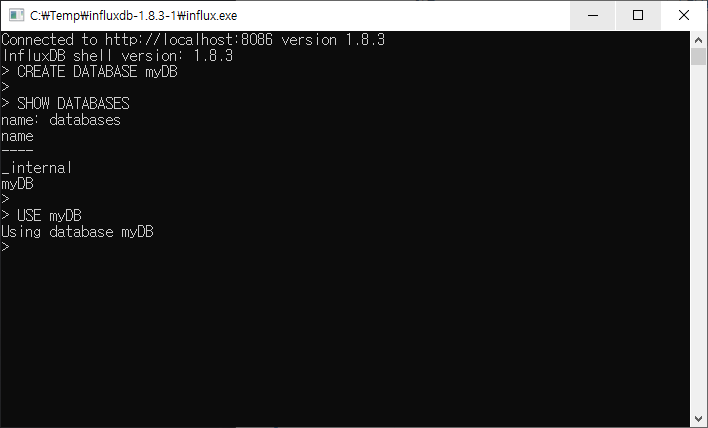
3. 데이터베이스 사용하기
생성한 데이터베이스를 사용하기 위해서 아래와 같이 입력한다.
USE [DBNAME]
4. 데이터 입력하기
| RDB | InfluxDB |
| database | database |
| table | measurement |
| column | key |
| Primary Key, indexed column | tag key (only string) |
| unindexed column | field key |
| SET of index entries | series |
관계형 데이터베이스에서 table이 시계열 데이터베이스에서는 측정의 의미를 가지는 measurement이다.
하나의 데이터베이스 안에는 여러 개의 measurement가 있을 수 있으며 여기서 중요하게 짚고 넘어가야 할 부분은 measurement의 구조이다.
이제 measurement 안에 수많은 데이터들이 저장될 것인데, 각각의 데이터는 Point라는 틀을 가진다.
Point라는 것은 데이터를 입력하는 순간의 시간적인 지점(point)을 말하는 것이며 이 Point 내부에는 여러 개의 key가 존재한다.
이 key에는 tag key, field key, time key가 있다.
tag key는 RDB에서 index key와 유사한 것으로 select문으로 조회할 때 기준이 된다.
또한 항상 string(문자열) 형태로만 들어올 수 있기 때문에 따옴표(')로 감싸줘야 한다.
field key는 데이터 자체라고 보면 된다.
time key는 측정 시점의 시간이 들어가는데 자동으로 입력되기 때문에 딱히 건들지 않아도 된다.
데이터를 삽입하는 방법은 다음과 같다.
INSERT [measurement 이름],[태그 이름1]=[태그 값1],[태그 이름2]=[태그 값2], ... [필드 이름1]=[필드 값1],[필드 이름2]=[필드 값2], ... [time key](Optional)여기서 주의해야 할 점은 태그 키 목록과 필드 키 목록, 필드 키 목록과 타임 키 사이에는 , (콤마)를 사용하지 않는다.
그리고 콤마 뒤에는 공백이 들어오면 안 된다.
또한 time key는 원래 자동으로 생성되기 때문에 명시적으로 넣어줄 필요는 없지만 명시적으로 넣을 수도 있다.
예시를 들어보자.
INSERT gyro,company='my_company',region='SouthKorea' X=15,Y=29,Z=31INSERT gyro,company='my_company',region='SouthKorea' X=15,Y=29,Z=31 121212121
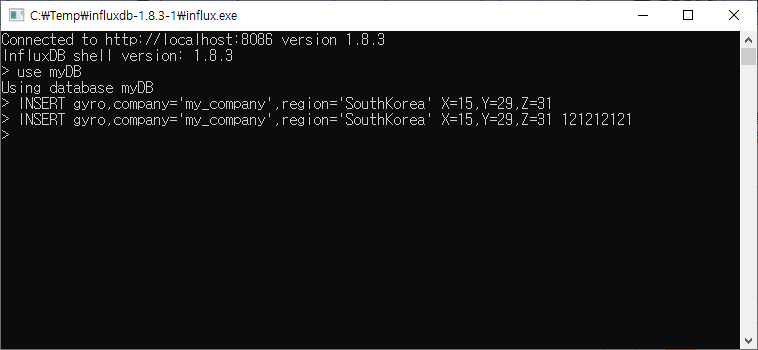
정상적으로 입력되었다면 아무 메시지도 안 나올 것이다.
time tag에 대해 조금 더 자세하게 설명하자면 influxDB는 UTC를 기준으로 1970년 1월 1일 0시 0분 0초로부터 지난 시간을 microseconds 단위로 나타낸다.
5. 데이터 조회하기
입력한 데이터를 확인하기 위해서는 SELECT 구문을 사용한다.
데이터 자체를 확인하기 전에 현재 사용 중인 데이터베이스에 어떤 measurements가 있는지, 어떤 series가 있는지부터 확인해보자.
show measurementsshow series
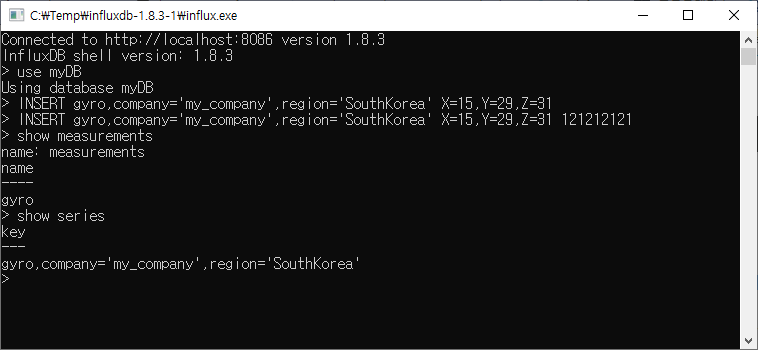
말 그대로 measurements와 series의 목록을 보여주는데 여기서 series는 measurement와 tag key를 세트로 합쳐놓은 구조체라고 보면 된다.
이외에도 show tag keys, field keys도 사용할 수 있다.
이제 현재 measurement에 저장되어있는 모든 데이터를 확인해보자.
SELECT * FROM [measurement 이름]

time key를 입력하지 않고 데이터를 삽입한 경우 자동으로 UTC 기준의 현재 시간을 가져온다는 것을 확인할 수 있다.
필드 전체가 아닌 일부를 가져오고 싶을 때는 이렇게 사용한다.
SELECT "X","Z" FROM gyro
SELECT로 데이터를 조회하는 방법에는 포스팅 하나를 차지할 정도로 많으니 이에 대해서는 다음번에 한번 다뤄보도록 하겠다.
6. 데이터, measurement, database 삭제
당연히 데이터를 삭제하는 경우는 없는 게 좋다.
하지만 테스트 중에 데이터를 잘못 생성할 수도 있기 때문에 간단하게만 살펴보자.
DELETE FROM gyro WHERE time<'2020-12-01'
데이터를 삭제할 때는 DELETE를 사용하면 되는데 WHERE으로 조건을 줄 수 있다.

measurement나 DB 자체를 삭제하고 싶을 때는 drop을 사용한다.
DROP MEASUREMENT gyroDROP DATABASE myDB
7. 마무리
InfluxDB의 기본 사용법에 대해 알아보았다.
여기까지 봤을 때 문득 이런 의문점이 들 수도 있다.
시계열 데이터는 초당 1초에 셀 수도 없이 들어올 텐데 오래된 데이터는 삭제하는 게 맞지 않을까?
물론 삭제하는 것이 좋고 DELETE나 DROP 없이 삭제할 수도 있다.
오래된 데이터들을 자동으로 삭제시켜주는 기능이 바로 Retention Policy라는 것인데 다음 포스팅에서 이것에 대해 알아보도록 하겠다.
'데이터베이스 (DB) > InfluxDB' 카테고리의 다른 글
| InfluxDB와 Python3 연동하기 (For Windows & Ubuntu) (1) | 2020.12.09 |
|---|---|
| InfluxDB에서 Retention Policy 설정하기 (0) | 2020.12.07 |
| InfluxDB 1.8 소개 및 설치 (For Windows & Ubuntu) (0) | 2020.12.04 |
